多轮对话提升自动化流程服务
 |
本文根据Chatopera联合创始人&CEO王海良老师在DataFunTalk人工智能技术沙龙“自然语言处理技术应用实践”中分享的《多轮对话提升自动化流程服务》编辑整理而成,在未改变原意的基础上稍做修改。
 |
今天主要分享两部分,一部分是技术分享,第二部分是介绍一下Chatopera提供的企业聊天机器人应用解决方案。目前开发企业聊天机器人很麻烦,需要用大量的数据,依赖机器学习和熟悉自然语言处理的专家,成本比较高,我们能提供快速落地、稳定的、低成本实现聊天机器人的方案,下图是我们的解决方案。

Chatopera面向企业业务人员发布了多轮对话设计器,用于设计满足企业需求的聊天机器人,从多轮对话设计器中可以导出对话应用。对话应用可以导入到智能问答引擎中,智能问答引擎是面向企业IT人员的,它可以管理聊天机器人,包括多轮对话、知识库、意图识别和监控接口使用情况。智能问答引擎暴露接口对外集成,也包含基于Web的管理控制台,这套方案可以支持将企业内部流程和在客服、营销过程中的话术转化为聊天服务,接入到企业微信、微信公众号等,从而提供企业的智能化和自动化。闲话不多说了,下面开始分享一些自然语言处理的知识。

语言模型是计算一个句子出现的可能性,比如我问机器人一个问题,那么它的不同回答出现的可能性是什么样的。自然语言处理经历过很多阶段,不同发展时期有不同的特点,经历过经验主义主导和理性主义主导的时期,前者主要是语言学家推出的一些方法,后者则大量使用统计学方法。自然语言处理又应用于很多任务中,比如机器翻译、信息检索和阅读理解,近年来取得重大突破的主要是基于统计学方法的。用大量的数据统计出语言的特征,从中找到规律,从而对给定输入预测出结果。第一位提出用数学解决语言问题的是香侬,他是信息论的开创者,也是人工智能之父。现在很多用于人工智能的方法更多的是来源于通信领域,比如最大熵、最大似然都来自于信息论。

检验一个语言模型的好坏是通过“困惑度”来衡量,就是你说了一个字,下一个字有几种可能,可能数越少说明语言模型越准确。描述一个语言模型的格式常用ARPA,很多工具都支持这种格式,用很大的语料训练形成一个文件,文件带有N-Grams的token列表,第一列是token,第二列是它出现的概率,通常是以Log10函数换算后的结果,第三列是backoff加权,主要用来平滑。计算一句话出现的可能性用途有很多,比如纠错中看那个字是错误的。公式7就是具体计算一句话可能性的,它将目标分成两个部分,然后分别求,右半部分是对应的backoff权值,如果它不存在,就使用1.0作为默认值,左半部分如果在语言模型中也不存在,就迭代计算。

如果解决一个翻译任务,就可以用历史数据去训练模型,我们的目的是得到一个函数,通过它预测未来输入的句子的翻译结果。我们不能知道完整的特征空间,但是基于大数定理,我们认为在训练数据很大的情况下,训练后的模型与完整特征空间是一致的,这就是用已知数据去拟合完整的特征空间,利用数学原理,我们能得到的解不一定是最优解,但可以保证是局部的最优。最大熵原理是指导这个求解过程的重要思想,它的核心就是对未出现的事件,认为是等可能的,这样保证熵最大。因为熵增定律认为系统总是朝着最无序,最混乱的方向发展,那么保证熵最大,可以最接近真实情况。上图可以用来描述最大熵模型,首先定义计算熵的公式,然后目标是最小化它的对偶问题(公式8),然后描述它的限制条件,限制条件为若干特征函数,特征函数的构造一般是输出值为0或1的函数,再一个条件就是对于一个输入x,各种输出的概率和是1。然后将目标函数和限制条件通过拉格朗日乘子法建立方程组,对每个方程求偏导,进行求解。这是一个凸优化问题。

中文分词、词性标注、命名实体识别是自然语言处理中的“三姐妹”,是其它任务的基础。中文分词这些年来出现了很多方法,在九几年的时候主要通过字典和人为指定的规则完成,比如MMSEG算法,提出语素自由度概念,前向或后向的算各种分词情况下的分数,然后确定最优解。2000年以后,多用机器学习算法,准确率也大幅提升,解决了识别新词等困难,有些分词器准确率能达到96%以上。隐马尔可夫模型是很经典的模型,也很简单,很多分词器基于它实现。使用隐马尔可夫模型可以解决三类问题:
- 概率计算问题:计算可观测序列出现的概率;
- 预测问题:根据可观测序列找到最有可能的隐藏状态序列;
- 学习问题:估计隐马尔可夫模型的参数。
隐马尔可夫模型包含五个参数:不可观测的状态,可观测的观测序列,初始状态概率向量,观测概率矩阵和状态转移概率矩阵。在中文分词中,由字构词法就是将状态分为(B,M,E,S),它们分别代表一个字出现在词汇的开始、中间、结尾或独立成词。近年来,基于条件随机场的分词效果超过了隐马尔可夫,主要是因为条件随机场能更充分的利用一个字的上下文关系,能更好的描述序列化任务,因为隐马设定了比较强的依赖,只是利用了前一个字。
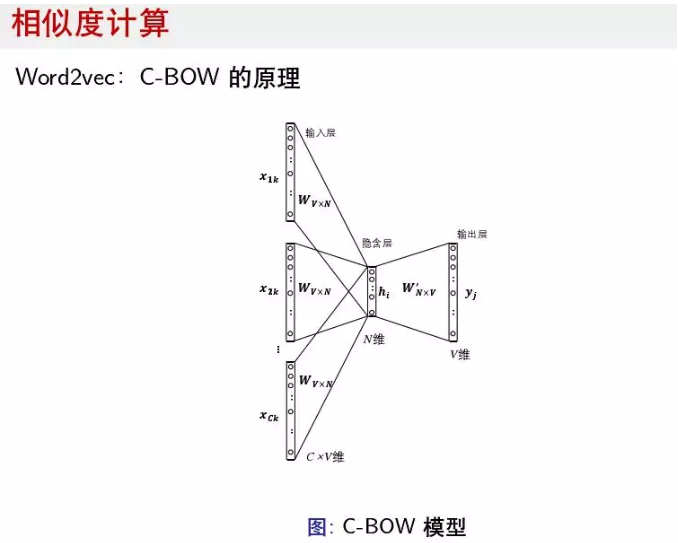
在很多自然语言处理任务中,比如搜索、摘要和关键词提取都与相似度计算关系很大,尤其是两个句子和两个词之间的相似度。目前基于词向量的相似度计算用的比较多的是Word2vec,它的网络设计是很简单的,比如C-BOW模型,就是利用前后词去预测当前词。Synonyms是一个开源的可以用于计算相似度的库,它融合了语义上的距离以及匹配,利用开源的算法和开放的wikidata数据制作的。
https://github.com/huyingxi/Synonyms
在最近受到了一些关注,在Github上,star数量在稳定增长,我是这个项目的作者之一,欢迎大家使用和提Issue。
 |
常见的信息检索系统就是基于倒排索引,在2011年以后,召回后进行排序时,又多用深度学习技术,比如Pointwise, Pairwise等方法。
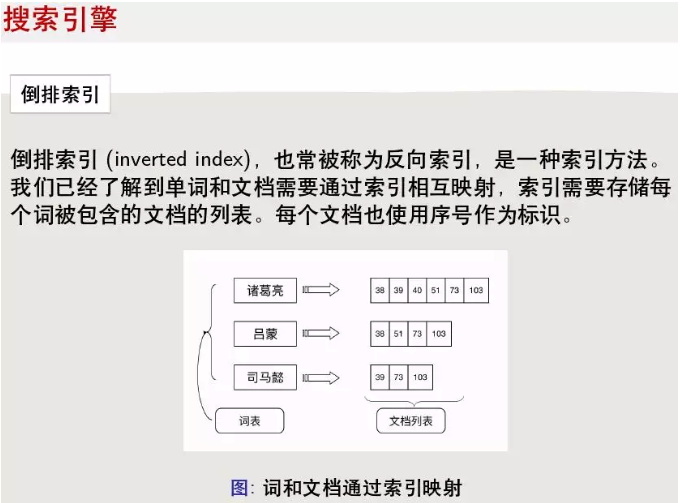
倒排索引是一个词可能出现在很多文章中,那么就将词建一个列表,然后出现它的文章都建一个id,然后这些文章按照递增的顺序关联到这个词上。在查询时,根据不同条件得到文章集合,使用归并算法输出。

Apache Lucene是帮助实现信息检索系统的开源项目,它的query语法很丰富,性能也很出众。Lucene的查询语法也给Chatopera团队实现聊天机器人的对话引擎很大的启发。另外在搜索时,Lucene也支持使用近义词,通过简单扩展、简单收缩、简单映射和姻亲扩展让检索更智能。

另外一个知名开源项目 - Elasticsearch也是面向企业快速搭建信息检索系统的,是实现搜索引擎的非常棒的项目,它的文档相关度计算如上图,它不但使用了TF-IDF、也支持对一个词进行加权,还根据文档长度进行规范化。

搜索引擎的评测标准有很多指标,比如MAP、MPP,基于混淆矩阵的准确率和召回率是经典的方法。准确率和召回率是矛盾的,所以,常使用二者结合起来计算的F1值评价,F1值越高,效果越好。
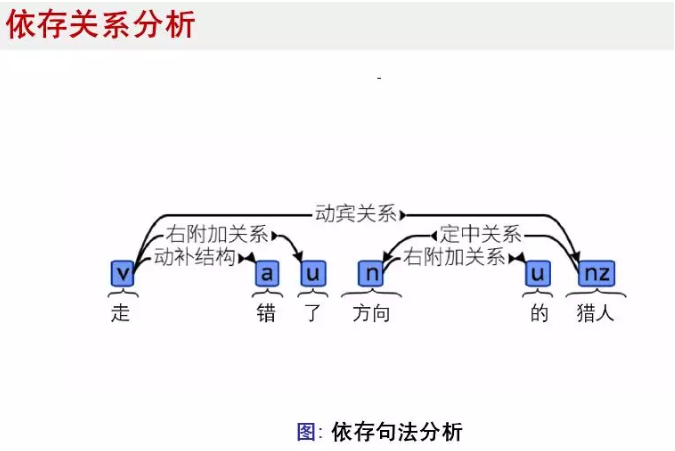
在自然语言处理中,另一个比较难的点就是分析词与词之间关系,在分词后,一个词在句子中充当什么成分。依存关系分析依赖于分词的结果,也依赖于词性标注的结果。标注依存关系数据集也是很难的任务,词之间的关系会有几十种。我个人认为,从近几年学术上的成果看,依存分析分析已经处于从学术向实际应用过渡的节点了,2017年在依存关系分析任务上,就出现了准确率95%的论文。

目前,用于依存关系分析的流行算法有基于Transition-based和Graph-based两种。Transition-based parser基本理念就是将待分析的句子放入buffer中,然后顺序进入parser,oracle是一个分类器,它会给出针对这个词作出哪种行为,比如SHIFT, 右附加关系,左附加关系。下面是有关依存关系分析的两个开源项目:
https://github.com/Samurais/text-dependency-parser # 经典的transition-based parser
https://github.com/elikip/bist-parser # 使用神经网络实现Oracle的Parser
以上内容是自然语言处理的部分,但是本次分享的主题是“多轮对话提升自动化流程服务”,目前信息检索服务不断向更智能的方向发展,搜索引擎公司越来越了解我们,但是在企业里,随着业务的发展,它更需要的是通过多轮对话完成流程服务,一问一答的服务解决不了太多问题。企业里对业务流程引擎有着极大的热情,业务流程引擎也在几十年的发展中,不断标准化,完善化。比如当前的标准BPMN2.0用50多个元素去帮助业务人员建模,编排流程服务。结合对业务流程引擎和自然语言处理的理解,Chatopera开发了对话引擎,并基于它开发了多轮对话设计器和智能问答引擎。

对话引擎是以自然语言为输入的,描述对话的,它根据这些脚本,梳理规则,形成机器人的思维逻辑导图。对话引擎也有自己的一套强大的语法规则,能让机器人更加智能。
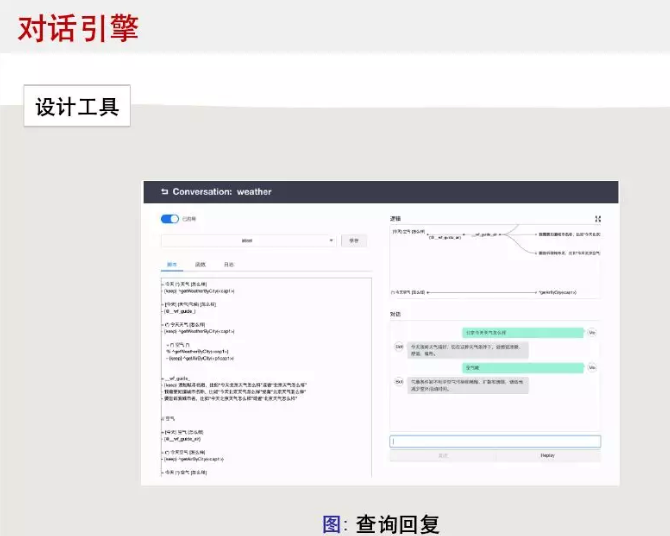
上图是多轮对话设计器的对话编辑窗口,左侧写脚本,右脚上是实时渲染的机器人思维逻辑导图,右下角是测试窗口。多轮对话设计器通过函数完成系统集成,比如在对话中依赖CRM或订单管理数据等,函数和脚本可以相互调用,这样能满足企业的各种业务需求,并且灵活调整。下面的链接提供一个具体的例子,怎么通过多轮对话设计器实现一个查询天气的机器人。
https://github.com/chatopera/conversation-sampleapp
在Chatopera,自然语言处理和机器学习主要应用于帮助业务人员快速实现聊天机器人,比如客服人员输入“订单下单后怎么查看物流状态”,那么这就话有哪些不同的说法,基于对话引擎,它的规则是什么样的,它的回复有几种可能。也就是,Chatopera利用先进的技术帮助业务人员写机器人的对话脚本。在Chatopera看来,这是企业实现聊天机器人过程中,一个重要的环节。那么,怎么做呢?一方面,要熟悉业务流程引擎的设计理念,比如流程状态机、流程的编排、企业业务人员的工作习惯等,另外一方面,要对信息检索、分词、近义词挖掘、依存关系和机器阅读理解等自然语言处理任务不断研究,持续创新。
今天分享的内容包括一些经典的、成熟的,同时,这些方法也能启发大家创新,比如分词的技术应用于机器阅读理解、Lucene的查询语法应用于多轮对话技术等。期待于大家进行更深度的交流,我今天的分享就到这里,想要进一步了解Chatopera的产品请访问:
https://docs.chatopera.com/
Subscribe to Chatopera S-Team Blogs
Get the latest posts delivered right to your inbox
